ความรับผิดชอบของผู้ดูแลระบบ Hadoop
บล็อกนี้เกี่ยวกับความรับผิดชอบของผู้ดูแลระบบ Hadoop กล่าวถึงขอบเขตของการดูแลระบบ Hadoop งานผู้ดูแลระบบ Hadoop เป็นที่ต้องการสูงดังนั้นเรียนรู้ Hadoop ทันที!

บล็อกนี้เกี่ยวกับความรับผิดชอบของผู้ดูแลระบบ Hadoop กล่าวถึงขอบเขตของการดูแลระบบ Hadoop งานผู้ดูแลระบบ Hadoop เป็นที่ต้องการสูงดังนั้นเรียนรู้ Hadoop ทันที!
Apache Spark เป็นพัฒนาการที่ยอดเยี่ยมในการประมวลผลข้อมูลขนาดใหญ่
Apache Hadoop 2.x ประกอบด้วยการปรับปรุงที่สำคัญเหนือ Hadoop 1.x. บล็อกนี้พูดถึง Hadoop 2.0 Cluster Architecture Federation และส่วนประกอบต่างๆ
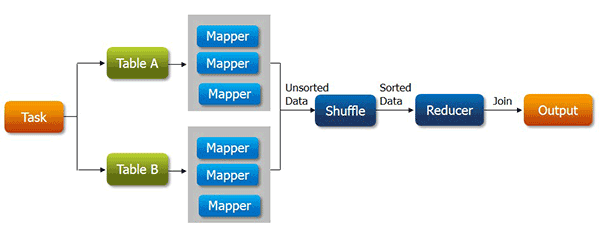
สิ่งนี้ให้ข้อมูลเชิงลึกเกี่ยวกับการใช้ Job tracker
Apache Pig มีฟังก์ชันที่กำหนดไว้ล่วงหน้าหลายฟังก์ชัน โพสต์มีขั้นตอนที่ชัดเจนสำหรับการสร้าง UDF ใน Apache Pig รหัสที่นี่เขียนด้วย Java และต้องใช้ Pig Library
มีสถาปัตยกรรม HBase Storage ประกอบด้วยส่วนประกอบมากมาย มาดูฟังก์ชั่นของส่วนประกอบเหล่านี้และรู้ว่ามีการเขียนข้อมูลอย่างไร
Apache Hive เป็นแพ็คเกจ Data Warehousing ที่สร้างขึ้นจาก Hadoop และใช้สำหรับการวิเคราะห์ข้อมูล Hive มีเป้าหมายสำหรับผู้ใช้ที่พอใจกับ SQL
การนำ Apache Spark ไปใช้กับ Hadoop ในระดับใหญ่โดย บริษัท ชั้นนำบ่งบอกถึงความสำเร็จและศักยภาพในการประมวลผลแบบเรียลไทม์
NameNode High Availability เป็นหนึ่งในคุณสมบัติที่สำคัญที่สุดของ Hadoop 2.0 NameNode High Availability with Quorum Journal Manager ใช้เพื่อแชร์บันทึกการแก้ไขระหว่าง Active และ Standby NameNodes
ความรับผิดชอบงานของนักพัฒนา Hadoop ครอบคลุมงานต่างๆมากมายความรับผิดชอบงานขึ้นอยู่กับโดเมน / ภาคส่วนของคุณบทบาทนี้คล้ายกับนักพัฒนาซอฟต์แวร์
แบบจำลองข้อมูล Hive มีส่วนประกอบต่อไปนี้เช่นฐานข้อมูลตารางพาร์ติชันและที่เก็บข้อมูลหรือคลัสเตอร์ไฮฟ์รองรับประเภทพื้นฐานเช่นจำนวนเต็มลอยคู่และสตริง
เหตุผล 4 ประการในการอัปเกรดเป็น Hadoop 2.0 พูดถึงตลาดงาน Hadoop และวิธีที่จะช่วยให้คุณเร่งอาชีพได้โดยเปิดโอกาสในการทำงานมากมาย
ในบล็อกนี้เราจะเรียกใช้ตัวอย่าง Hive และ Yarn บน Spark ประการแรกสร้าง Hive and Yarn บน Spark จากนั้นคุณสามารถเรียกใช้ตัวอย่าง Hive and Yarn บน Spark
วัตถุประสงค์ของบล็อกนี้คือการเรียนรู้วิธีการถ่ายโอนข้อมูลจากฐานข้อมูล SQL ไปยัง HDFS วิธีการถ่ายโอนข้อมูลจากฐานข้อมูล SQL ไปยังฐานข้อมูล NoSQL
Cloudera Certified Developer สำหรับ Apache Hadoop (CCDH) ช่วยเพิ่มความก้าวหน้าในอาชีพการงาน โพสต์นี้จะกล่าวถึงประโยชน์รูปแบบการสอบคู่มือการศึกษาและข้อมูลอ้างอิงที่เป็นประโยชน์
บล็อกนี้ให้ภาพรวมของสถาปัตยกรรม HDFS High Availability และวิธีการตั้งค่าและกำหนดค่าคลัสเตอร์ HDFS High Availability ในขั้นตอนง่ายๆ
Apache Kafka ยังคงได้รับความนิยมอย่างต่อเนื่องเมื่อพูดถึง Real-Time Analytics นี่คือมุมมองจากมุมมองด้านอาชีพการพูดคุยเกี่ยวกับโอกาสในการทำงานและความต้องการงาน
Apache Kafka มีระบบส่งข้อความที่มีปริมาณงานสูงและปรับขนาดได้ทำให้เป็นที่นิยมในการวิเคราะห์แบบเรียลไทม์ เรียนรู้ว่าบทช่วยสอน Apache kafka สามารถช่วยคุณได้อย่างไร
บล็อกโพสต์นี้เป็นการเจาะลึกเกี่ยวกับ Pig และหน้าที่ของมัน คุณจะพบกับการสาธิตวิธีการทำงานบน Hadoop โดยใช้ Pig โดยไม่ต้องพึ่งพา Java
บล็อกนี้กล่าวถึงข้อกำหนดเบื้องต้นสำหรับการเรียนรู้ Hadoop, Java ที่จำเป็นสำหรับ Hadoop & คำตอบ 'คุณต้องการ Java เพื่อเรียนรู้ Hadoop' หรือไม่ถ้าคุณรู้จัก Pig, Hive, HDFS